
Google’s recommendation to use the new Author.url link to a central profile of the author’s bio harkens back to the days of rel=author and Google Authorship. The gents also discuss standard updates to Google tools, news on the Links Spam Update, optimizing Google My Business categories and services, and how to interpret and react to poor Google indexation of a website.
Noteworthy links from this episode:
- Changes in Search for minors
- Magento Critical Vulnerabilities Announced by Adobe
- Google adds author URL property to uniquely identify authors of articles
- Google Link Spam Update Still Rolling Out Over 3 Weeks Later
- Top Stories Images Aren’t Showing in Google Search
- Google’s tool to report indexing bugs is now available in the U.S.
- Google’s legacy structured data testing tool is now gone
- Adding services to primary category vs secondary category
Transcription of Episode 413
Ross: Hello, and welcome to SEO 101 on WMR.fm. episode number 413. This is Ross Dunn, CEO of Stepforth Web Marketing and my co-host is my company’s senior SEO Scott Van Achte. Having a good day, bud?
Scott: I’m having a fantastic day. It’s a beautiful day on the west coast so I can’t complain.
Ross: I agree. I didn’t get much sleep last night but I think I’m just running on adrenaline. It’s working out but the crash won’t be too nice. It’s good right now.
Scott: That’s what the weekends are for.
Ross: You just push yourself harder to have fun then.
Anyway, let’s start off with some other news here. You posted a couple things I haven’t heard about so go for it.
Scott: Yeah, the first couple are just relatively minor but noteworthy. I guess pun intended without intending it. Google has made some changes in Search for minors. I guess due to all the changes with COVID and more and more kids are online and sharing information, that sort of thing. Google has made a few policy updates and I’ll just quickly touch on those. Those under 18 years of age or their parents or guardians can now request removal of their images, so photos of themselves from Google search results, which is great. I feel like that should be for anybody, not just minors, but we’ll take what we can get. This will not remove the image from the internet. Of course, Google can’t access third party sites, as we all know, but it will prevent images from showing up in search results. If you find your kids are showing up in a search for something undesirable, or even anything at all for that matter, there is now a way or there will be. Google is working on this in the next few weeks or months. There will be a process to have that photo removed from search, which is great.
YouTube is also making some changes to the default upload mode. They’re switching the default upload mode of videos to private for kids aged 13 to 17 and safe search will automatically be turned on for those under 18. I’m kind of surprised that it wasn’t already, but that’s great. Who knows what my kids are looking at. I tried to spy on them but I think my oldest has learned how to clear her history. Luckily, she’s very trustworthy and I’m not worried about what she’s up to. She’s just one of those kids but still, they’re getting too tech savvy. It’s even at the point where when I can’t do something on my phone, I ask her and she’s like, “Oh, you just do this? I’ll do it for you.” She’s done. I’m like, “how did you do that?”
Ross: We’re already those people.
Scott: Yeah, I know. I feel like my father, I don’t know. I think he had a cordless [phone]. The cordless phone was the ultimate tech event that he ever experienced.
Then finally, Google Ads is also expanding safeguards to prevent age sensitive ad categories from being shown to teens and will block ad targeting based on age, gender and interests of people under 18. I guess that’s good news, help keep people from sending specific ads to your kids. Of course, that all requires that kids be logged into their own accounts and not their parents accounts. Otherwise, you have to wonder, how many kids are logged into their own accounts?
Ross: Oh, maybe it’s a whole ‘nother topic. There’s lots to it.
Scott: There certainly is. At any rate, I guess the gist of this is that Google is making efforts to protect kids. That’s never a bad thing.
Ross: Definitely worth mentioning on the show. I know it’s not SEO 101 stuff but if you don’t listen to many other podcasts, I think it’s good that we all know this.
Now, the next bit is about Magento platform that we don’t use very often. Thankfully, we’re not a big fan of it. There’s a critical vulnerability that Adobe announced. Apparently there’s a patch with 33 security enhancements, including fixes for 16 vulnerabilities rated critical that need to be applied. Anyone out there that has Magento, make sure you update immediately if you haven’t already been prompted to and as Scott mentioned here in the notes, backup first. There’s some backward compatibility issues so you may end up with a broken site and you need to make sure you can restore it again, if anything goes wrong.
Apparently there’s a patch with 33 security enhancements, including fixes for 16 vulnerabilities rated critical that need to be applied. Anyone out there that has Magento, make sure you update immediately if you haven’t already been prompted to and as Scott mentioned here in the notes, backup first. There’s some backward compatibility issues so you may end up with a broken site and you need to make sure you can restore it again, if anything goes wrong.
Scott: It’s good. Like, do I prefer to have an easy-to-breach security risk of a website or one that doesn’t work? Let’s just hope that you don’t have to resort to those backups or that another patch comes out to fix those compatibility issues.
Ross: Yeah, and depending on your hosting solution, you could also perhaps have a sandbox scenario where you can test all this before you put it live. That would be ideal.
All right, some SEO news here. Google has added an author URL property to uniquely identify authors of articles. This is for anyone who’s been in the SEO industry for a while, a bit of a blast from the past. We’ve been seeing hints of Google wanting to see E.A.T.: expertise, authoritativeness and trustworthiness around articles. Part of that is being connected; an article being connected or content being connected to a person who has those qualities. They’ve been looking at different ways of connecting the dots. Back in 2012, they did this with authorship, where it was a “rel=author”, and then you would point to your Google Plus page, which would then have links to the other places you were connected. It was actually really well done. It’s odd that they just pulled it apart and dismissed it all, frankly, especially since it’s apparently coming back in some regards. I mean, no, it’s not considered “authorship” but the parallels are pretty funny. In this case, the URL property, you can use the sameAs property. This is all in the schema. It is more, again, just structured data, stuff we talked about in the past that you add to the page that explains where it’s connected to, who the author is, all that stuff. In this case, there’s an author.URL property that you can do instead of sameAs. It’s a new recommended property that is supposed to be linked to the author’s social media page, About Me page, a biography page, or some other page that identifies the author. This is really important stuff, especially if you’re following anything on the Knowledge Graph. It’s a whole ‘nother ball of wax, frankly, I’m trying to figure out how gentle I want to get here. If you, let’s say, typing up a person’s name of significance, generally, their knowledge panel will show up in the right side of the search results and then anything they’ve been connected with: can be various profiles, latest articles, photos, you name it. This is just another way to connect all those dots in the Knowledge Graph and make it easier on Google to not only work the Knowledge Graph, but also, to help them determine the quality of content on a different level than just analyzing the content. It’s really interesting and, again, extremely similar to the old path they had with authorship. I like seeing it again, it’s overdue. It’s a very logical approach and I’m glad they’re bringing it back. Anything else you want to add there?
Scott: No, I think you got it. It’s really surprising, it works so well and then it was just one of those things that Google pulled the plug on. I feel like we knew it had to come back eventually. It was just such an obvious addition to E.A.T. and helping a website’s authority. It’s good to see that they’re taking some steps to bring that back.
Ross: Yeah and you did some digging. We were curious when it started and ended. It started June 2011 and ended in 2014. Anyway, I guess wiser parties came into play and decided that this is important. Anyway, I guess it was before it’s time.
Scott: I was joking earlier that I bet they knew that they were going to pull Google Plus a few years after that. So they thought, “let’s get rid of everything associated with it first to make life easier later.” Could you imagine if they pushed authorship hard, right up until the end of Google Plus and had authorship as a really strong contributing factor in the SERPs, they wouldn’t be able to pull the plug on Google Plus, they’d need an alternative or it would screw up their whole algorithm.
Ross: Yeah. It’s true. Although they love messing with us so they probably just added another. Who knows? Another thing for us to do.
Scott: Google Plus Plus
Ross: Yeah, exactly. All right. What’s next?
Scott: We have Google spam update still rolling out over three weeks
Ross: I put that in there.
Scott: Yeah. Not a big surprise. I feel like all the updates now, none of them are flip a switch and done these days. They’re all being spanned out over multiple updates or multiple weeks.
Ross: Yeah, so this Google link spam update was released on the 26th, I believe, of July. They said it would take a few weeks and Danny Sullivan has been piling up saying, “well, it’s still not coming. It’s not done yet, probably next week.” 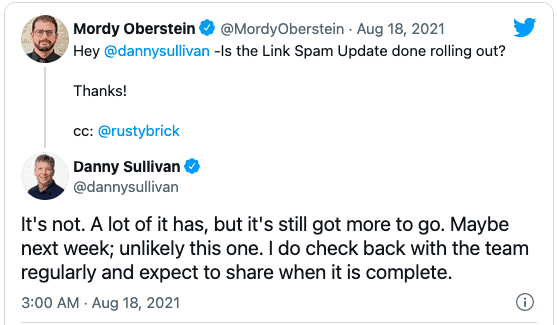 Honestly, who cares? It’s interesting and for those that want to follow this stuff, what is it going to do? That’s anyone’s guess exactly how much impact it will have. The idea is they’re trying, I assume based on what I’ve been reading, that they’re trying just to improve their ability to track and identify links that should be noted as paid or sponsored so that they can nullify them. So they don’t help the people who have obtained them. In more extreme circumstances, penalize in a manual fashion, the people who are doing it blatantly and to a great extent. That’s it, we don’t know the extent of how much impact that’s gonna have until it’s fully rolled out, I guess. It’s probably a small update, though. They’ve done a lot of the big sweeping, I hope they have anyway, big sweeping adjustments already. I guess these are more micro fixes.
Honestly, who cares? It’s interesting and for those that want to follow this stuff, what is it going to do? That’s anyone’s guess exactly how much impact it will have. The idea is they’re trying, I assume based on what I’ve been reading, that they’re trying just to improve their ability to track and identify links that should be noted as paid or sponsored so that they can nullify them. So they don’t help the people who have obtained them. In more extreme circumstances, penalize in a manual fashion, the people who are doing it blatantly and to a great extent. That’s it, we don’t know the extent of how much impact that’s gonna have until it’s fully rolled out, I guess. It’s probably a small update, though. They’ve done a lot of the big sweeping, I hope they have anyway, big sweeping adjustments already. I guess these are more micro fixes.
Scott: Yeah, I agree but the one nice thing about updates like this, so many updates, well primarily the core updates, if you get burned, you really don’t have recourse to fix it. I mean, you do, but it’s a fight, right? Whereas in this case, if you do get hit by this, it’s a pretty safe bet that you lost links that were counting, that were no good, and now they’re gone. The fix is, probably, to get new good links. Probably. I mean, I’m taking a guess here but I think it’s a pretty accurate guess that that’s going to be your fix if you get burned by this one.
Ross: True enough. All right. Top Stories images aren’t showing in Google search.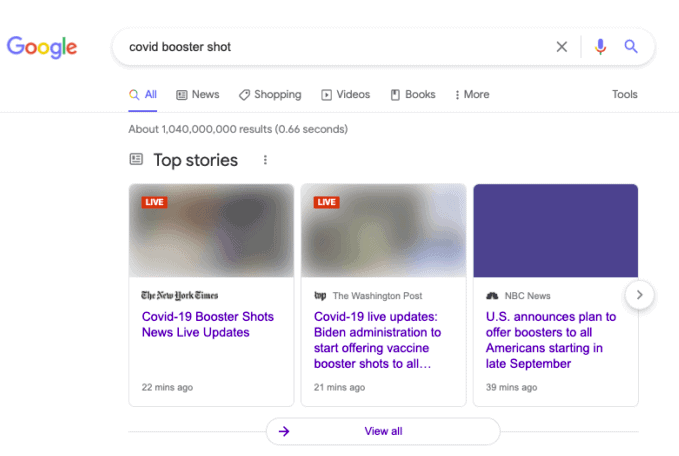
Scott: Yeah. So Wednesday morning, the 18th, there was a bug in search results for the Top stories results that sometimes pop up. If you do a random search, in this case, one example is COVID booster shot and you see a handful of top news stories appear up at the top and the image thumbnails associated with those are blurry. They’re just not working. I wasn’t even going to mention this because I figured by the time we got around to recording, it would be fixed and it’s still not fixed. I’m able to reproduce it so if you happen to see that and maybe you’re one of the websites that is showing the news result, and you’re seeing your images as being blurry and starting to panic, like “what’s going on with my site.” Rest assured it is not your website or your problem, Google will fix it and hopefully it doesn’t result in a reduced click through rate in the meantime. Just another Google bug floating around.
Ross: Yeah, news sites are not too pleased. Can’t imagine that’s good for them.
Scott: It can’t be good for the click through, I bet. We don’t have any big news clients but I’m sure John is seeing this. If you’ve got a high traffic site that relies on appearing in those top stories, I bet it’s having a big impact on click through rates. I would be surprised it wasn’t.
Ross: Alright, let’s take a quick break and when we come back we’re going to talk about an indexing bug or the way to report indexing bugs
Welcome back to SEO 101 on WMR.fm. Hosted by myself Ross Dunn, CEO of Stepforth Web Marketing and my company’s senior SEO, Scott Van Achte.
So Google’s tool to report indexing bugs is now available in the US. 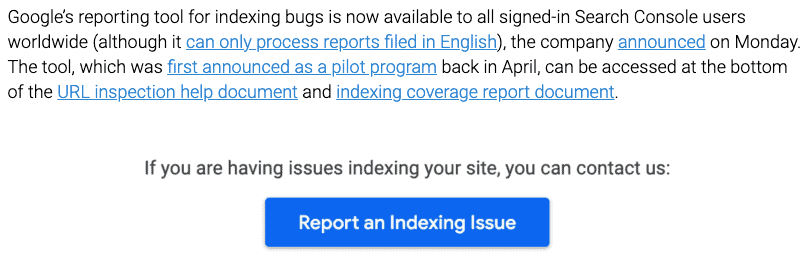 The concept of this is, and I guess in US because we’re still not seeing it in Canada and elsewhere but at least it’s available somewhere. The concept here is if you notice a bug where something is not being indexed in your site, and it’s just inexplicable, all the hell files, everything you’ve looked for and it just does not give you the insight you need, you can report the indexing issue now through Google Search Console. This is intended as a reporting channel for suspected indexing bugs only, though. So they’re going to walk you through some questions and stuff after you try to submit, I guess, just trying to determine if there’s any way they can eliminate the question before it ends up getting sent to Googlers who will need to spend the time on it. If there is a bug and they identify that you’re correct that there is something, they may reach out and work with you to correct it. They may not, but hopefully they will attend to it. There are a number of them that have appeared in the last while. Different communities and forums are mentioning them so too many to count, I’m sure. Google is one monstrous machine so I’m sure there’s lots of issues out there and this is good. It’s a nice way for people to be able to report issues.
The concept of this is, and I guess in US because we’re still not seeing it in Canada and elsewhere but at least it’s available somewhere. The concept here is if you notice a bug where something is not being indexed in your site, and it’s just inexplicable, all the hell files, everything you’ve looked for and it just does not give you the insight you need, you can report the indexing issue now through Google Search Console. This is intended as a reporting channel for suspected indexing bugs only, though. So they’re going to walk you through some questions and stuff after you try to submit, I guess, just trying to determine if there’s any way they can eliminate the question before it ends up getting sent to Googlers who will need to spend the time on it. If there is a bug and they identify that you’re correct that there is something, they may reach out and work with you to correct it. They may not, but hopefully they will attend to it. There are a number of them that have appeared in the last while. Different communities and forums are mentioning them so too many to count, I’m sure. Google is one monstrous machine so I’m sure there’s lots of issues out there and this is good. It’s a nice way for people to be able to report issues.
Scott: This sort of thing is fantastic. I mean, how often have you got a page that should be indexed and simply isn’t and it’s inexplicable. You’ve got all the nav set up properly, you got a high quality content page with links coming in and whatever and it just doesn’t get indexed. We don’t see it super often but it certainly happens. This is great that if it’s related to a bug, which I’m sure it occasionally at least is, there’s a bit of an avenue to go down to get that fixed.
Ross: Yeah, and you potentially are actually getting connections with Googlers, which anyone who’s been in the market a while knows, that’s not something you scoff at. Most of the time, they just fall on deaf ears.
Scott: Yup.
Ross: Now, what’s next year?
Scott: Yeah, so we talked about this a while ago, it’s been coming down the pipe for a few months, at least, the structured data testing tool that Google has, is now officially dead. Sort of, they announced a while ago that Google was getting rid of it in favor of the rich results tester. If you would ever use the structured data testing tool, you would have seen a pop up come up that said, “this is going away, you want to use this tool instead.” The problem with that was the rich result tester does not do the same thing as the old validator did. Ultimately, what happened is, the validator is now and has been moved over to schema.org. so you can find it at validator.schema.org and the rich results test is live as well. If you go to the old structured data testing tool, there are two links pointing you to the validator and one pointing you to the rich results tester. Probably not a super critical deal for anybody because the validator is available elsewhere but just a reminder, you might want to update your links. If you’ve got links to the validator through your blog posts, the quality will be higher if you have those pointing to the right place. Check your bookmarks anywhere that you may be using that.
Ross: For listeners who aren’t familiar with this, what’s the difference between the validator and the rich results tester?
Scott: The validator checks all of your structured data markup, and whether it’s valid for search results or not, it’ll tell you everything that you’ve got marked up that it can find and tell you what’s on that particular page. The rich results test is specific, in that it won’t show you everything, it will only extract marked up content that qualifies to be potentially a rich result so you don’t get a complete picture. They’re both good tools for different reasons because you may have content marked up that won’t appear as a rich result but it should be marked up. You kind of want to use both tools, really. The rich results tool is more specific for what will directly appear or can directly appear in search results. The validator checks all of your markup on that page, regardless if it is useful or not.
Ross: Excellent. All right. Now for some local SEO news. Listeners know, I love checking out the local search forum. There’s always some fascinating things going on there. It’s really a place for people to post issues they’re having that are cutting edge, literally now and get some experts popping in to answer. It’s a really good place to be. This particular one was a very day-to-day question I noticed but then I got drawn into it. The question was regarding primary category versus secondary categories in Google My Business. When you’re filling out your Google My Business profile, it’s obviously best to maximize it, fill everything out you possibly can. One of the questions this particular person had was whether or not they should be adding specialties, in this case, some medical clinic to the category that makes the most sense, such as how many they should be adding to the secondary versus the primary. The primary is medical clinic, the secondary is: Doctor, Medical Center, Wellness Center, Family Practice, Physician, General Practitioner. He asked, “should I be adding specialties to the category that makes the most sense, we offer a wide range, or does it have more weight to add it to the primary category? More generally, do services even have an effect on ranking?” Some say they do, some say they don’t. This is services now, he’s switched this a bit. Services are a different section but I think he’s asking whether or not by adding these, they are going to have any effect. It’s a two-fold answer and Joy Hawkins did a great job of responding, actually quite succinctly. 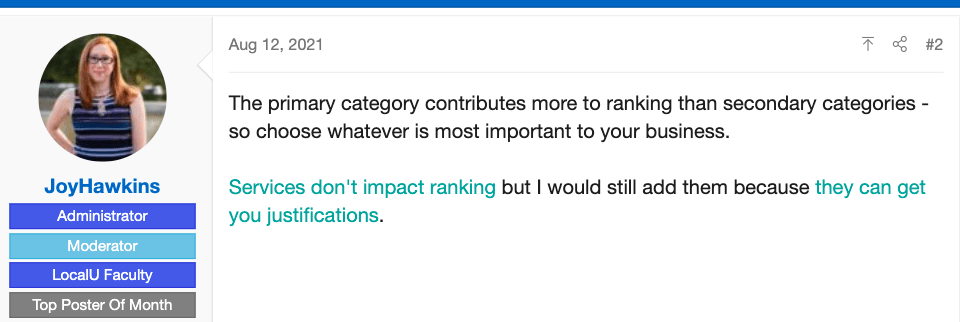 The primary categories are really the only one that has a lot of significant amount of weight in rankings. The secondaries have less. Fill them out but don’t stress too much about that. When it comes to services, and this is where you can add in what you offer and a little blurb about each thing you offer in your business, they don’t actually have any impact on rankings. It’s similar to a meta description tag on your web pages, it’s great to have it, helps the click through rate but it doesn’t do anything for rankings. The same thing applies here. They don’t help with rankings but they do help with click through rate and the reason why is if someone’s looking at your Google My Business listing and opening it up and looking through and seeing what you do, they’re obviously going to see a lot more. Also, when they do a search and one of the examples clearest, i thought, was someone looking for someone to weed their lawn So a lawn weed services or weeding services. Because this particular business had mentioned weed control in their services listing, and this is within Google My Business profile, below their result, it said that the checkmark provides weed control. That came directly from the Services section of their Google My Business listing. That wouldn’t be there if they hadn’t filled that out. That’s what is actually called, in Google’s world here, justification. Yes, this is something they do. So, this is a person you should consider calling. This is why we’re showing them in the Google Local results, in the map, in the local pack.
The primary categories are really the only one that has a lot of significant amount of weight in rankings. The secondaries have less. Fill them out but don’t stress too much about that. When it comes to services, and this is where you can add in what you offer and a little blurb about each thing you offer in your business, they don’t actually have any impact on rankings. It’s similar to a meta description tag on your web pages, it’s great to have it, helps the click through rate but it doesn’t do anything for rankings. The same thing applies here. They don’t help with rankings but they do help with click through rate and the reason why is if someone’s looking at your Google My Business listing and opening it up and looking through and seeing what you do, they’re obviously going to see a lot more. Also, when they do a search and one of the examples clearest, i thought, was someone looking for someone to weed their lawn So a lawn weed services or weeding services. Because this particular business had mentioned weed control in their services listing, and this is within Google My Business profile, below their result, it said that the checkmark provides weed control. That came directly from the Services section of their Google My Business listing. That wouldn’t be there if they hadn’t filled that out. That’s what is actually called, in Google’s world here, justification. Yes, this is something they do. So, this is a person you should consider calling. This is why we’re showing them in the Google Local results, in the map, in the local pack. 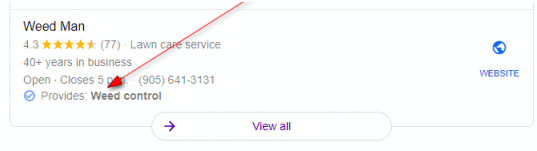
I know there’s a lot to unpack there but the simple fact is, it’s good to fill all this stuff out. The primary category is most important, the second category is less important. Services don’t have an impact on rankings but do help click through rate. There you go. Perfect. Next up…
Scott: What is next? Oh, it’s me. Mueller files here. I guess the hint is that a site:search does not show all pages. If you’re not familiar, we’ll quickly go over that. If you go into Google and do a search for site: and then your website address, site: www.stepforth.com, hit enter. Google spits out a whole bunch of URLs from your website. Someone had asked in a recent ‘Ask Googlebot’ video installment, “all of my URLs are indexed and when I check in Google one by one, the total number of URLs is 180 but in Google SERPs only 28 URLs show. Why is that?” So John responded, “The short answer is that a site query is not meant to be complete, nor used for diagnostic purposes. The query limits the results to a specific website, it is not meant to be a comprehensive collection of all the pages from that website. As a lot of you may know, if you are keen on finding how many pages Google has indexed from your website, then use Search Console instead.” There you have it, if you’ve been doing a site:search and wondered why you’re seeing what you’re seeing, don’t worry about it. If you really want to know what you have indexed, have a search console account. If you don’t, you should have had one a while ago so you might want to create one and you can go into the coverage report and see what is indexed and if something is not indexed, you can see, typically you can see why it isn’t. Not everything ends up being as cut and dry as we’d like but often it will show up there. That’s much better for troubleshooting. To be fair, even for my experience, I find Search Console isn’t 100% perfect but it’s what we’ve got. That’s why you should be doing it. Although a site: search is a good idea because you might still see things that you didn’t know were happening. Often I’ll do a site: search and if there’s an issue with your indexing or maybe somehow robots.txt is playing a factor in there, and it’ll say, “description not available due to robots.txt” or something like that. It’s a good idea to still check that but don’t worry about the quantity of pages and which pages specifically are appearing.
“all of my URLs are indexed and when I check in Google one by one, the total number of URLs is 180 but in Google SERPs only 28 URLs show. Why is that?” So John responded, “The short answer is that a site query is not meant to be complete, nor used for diagnostic purposes. The query limits the results to a specific website, it is not meant to be a comprehensive collection of all the pages from that website. As a lot of you may know, if you are keen on finding how many pages Google has indexed from your website, then use Search Console instead.” There you have it, if you’ve been doing a site:search and wondered why you’re seeing what you’re seeing, don’t worry about it. If you really want to know what you have indexed, have a search console account. If you don’t, you should have had one a while ago so you might want to create one and you can go into the coverage report and see what is indexed and if something is not indexed, you can see, typically you can see why it isn’t. Not everything ends up being as cut and dry as we’d like but often it will show up there. That’s much better for troubleshooting. To be fair, even for my experience, I find Search Console isn’t 100% perfect but it’s what we’ve got. That’s why you should be doing it. Although a site: search is a good idea because you might still see things that you didn’t know were happening. Often I’ll do a site: search and if there’s an issue with your indexing or maybe somehow robots.txt is playing a factor in there, and it’ll say, “description not available due to robots.txt” or something like that. It’s a good idea to still check that but don’t worry about the quantity of pages and which pages specifically are appearing.
Ross: Have you seen that? I haven’t seen that in ages now, “description not available due to robots.txt.” I don’t think they show that anymore.
Scott: Yeah, I don’t know. When was the last time I saw that? I feel like it wasn’t that long ago.
Ross: Let me know if you see it again because I’d be interested in knowing. I once upon a time thought it would be cool to have a tool that could identify sites that had that issue because sometimes it’s a mistake and it’d be good to let them know.
Scott: Yeah, absolutely.
Ross: One thing that gets to me about this is once upon a time you do a site:stepforth.com. just put that into Google in the search, there’s no spaces or anything, and you would get a fairly comprehensive listing of every page, but then they removed that ability so I don’t know why the hell they left the site:search option.
Scott: Well, I guess if you’re trying to do an advanced search of the content on your website, to find a specific page, that would be a good use for it.
Ross: Fair enough.
Scott: Even John says “not used for diagnostic purposes,” but there are some diagnostic uses for it, as it is. You really just have to know that it’s highly limited and you’re not going to get a comprehensive response out of Google on that search.
Ross: That’s too bad too, because it was really kind of a fun and effective method during competitor analysis when we did that a lot.
Scott: Oh, we used to use it all the time.
Ross: It would be a great indicator of just how well indexed a website was. Yeah, too bad. Well, next and another Mueller file is, Google: it’s normal for 20% of a site not to be indexed. This was a really good response and I’ll try and unpack this a little bit for you. In this case, a person was saying that, “20% of his pages are not getting indexed. It says they’re discovered but not crawled. Does this have anything to do with the fact that it’s not crawled because of potential overload of my server? Or does it have to do with the quality of the page?” John’s response is, it’s probably a little of both. So usually, if we’re talking about a smaller site, and it’s mostly not the case that we’re limited by the crawling capacity, which is the crawl budget side of things. If we’re talking about a site that has millions of pages, then that’s something where I would consider looking at the crawl budget side of things, but smaller sites, probably less.” As usual, it’s “it depends” but I think the real meat of this comes in later on, he continued his answer, he says, “with regards to the quality when it comes to understanding the quality of the website, that is something that we can take into account quite strongly with regards to crawling and indexing the rest of the website. So if you have five pages that are not indexed at the moment, it’s not that those five pages are the ones we would consider low quality, it’s more that overall, we consider this website may be a little bit lower quality, and therefore we won’t go off and index everything on the site.” He suggests taking a step back and trying to reconsider the overall quality of the website and not focus so much on technical issues for those pages. This comes up so often that I just felt we needed to cover it again. If your site isn’t getting indexed, you’re not getting the visibility you deserve, Google Search Console can really shine a light on this. If that’s the case, then it’s quality. Most of the time, it’s quality, or just the fact that you’re not known. Typically, it’s because you don’t have great quality or you haven’t done a good job of at least showing someone that you have it. You need to get out there. The old moniker, you can’t just build it and they will come. It doesn’t work that way. You’ve got to have something and make sure it’s worthwhile and it earns the right to rank. As dearly departed Dana Lookadoo always said, earn the right to rank. It’s important. It’s not easily done in many cases so make sure the content is outstanding.
Ross: Okay, wow.
Scott: That was a lot.
Ross: That was a lot. We usually have some questions but it’s been a little quiet on the Facebook forum. Please do jump in there and ask some questions. It’s free. You don’t get free consultations from us very often and we’d love to provide it for the show and help everyone out.
Well, on behalf of myself Ross Dunn, CEO of Stepforth Web Marketing and my company’s senior SEO, Scott Van Achte, thank you for joining us today. Remember, we have a show notes newsletter, you can sign up for it at SEO101radio.com where you don’t miss a single link and you can refresh your memory of a past show at any time. We are a little bit behind on that so I do apologize for those who are waiting for the next episode. We’re switching around a little bit of staff and just training them on doing that. Anyway, have a great week and remember to tune in to future episodes which air… well, I’d say every week but you know what it’s like these days, every two weeks on WMR.fm.
Scott: Thanks for listening, everyone.